



.webp)




















































Bảng xếp hạng AI Android mới nhất GPT-5.5 vượt Gemini DeepSeek

Để mang lại cái nhìn khách quan nhất về năng lực của các mô hình ngôn ngữ lớn (LLM), Google đã xây dựng một hệ thống đo lường chuyên biệt cho hệ sinh thái của mình. Mới đây, bản cập nhật danh sách thử nghiệm đã mang đến nhiều kết quả bất ngờ, làm thay đổi cục diện cuộc đua công nghệ giữa các ông lớn như OpenAI, Google và các thế lực AI mới nổi.
| Tóm tắt chung về bảng xếp hạng AI Android mới nhất:
|
Android Bench là gì?
Android Bench là bộ tiêu chuẩn kiểm thử chính thức do Google phát hành nhằm đánh giá một cách toàn diện năng lực của các mô hình AI trong việc hỗ trợ phát triển ứng dụng Android. Khác với các bài kiểm tra lý thuyết chung chung, hệ thống này tập trung vào các nhiệm vụ cốt lõi mà một lập trình viên phải đối mặt hàng ngày như viết mã nguồn, sửa lỗi hệ thống, và tối ưu hóa hiệu năng ứng dụng.

Điểm làm nên uy tín của Android Bench chính là việc các bài thử nghiệm được thiết kế dựa trên các kịch bản thực tế lấy từ kho mã nguồn mở GitHub. Mỗi chuỗi kiểm thử tiêu chuẩn bao gồm 100 tác vụ phát triển phần mềm khác nhau, và để đảm bảo tính khách quan tối đa, mỗi mô hình sẽ phải thực hiện chuỗi tác vụ này lặp đi lặp lại qua 10 lần tính toán độc lập.
Kết quả cuối cùng sẽ phản ánh chính xác khả năng đọc hiểu cấu trúc thư mục phức tạp, xử lý sự thay đổi của các phiên bản Android API, và đưa ra giải pháp lập trình tối ưu nhất. Đây được xem là chiếc "kính hiển vi" chân thực giúp các kỹ sư công nghệ lựa chọn trợ lý AI phù hợp cho dự án của mình.
GPT-5.5 dẫn đầu bảng xếp hạng AI cho phát triển Android
Phiên bản cập nhật mới nhất của Android Bench đã cho thấy sự thống trị của OpenAI, thiết lập một tiêu chuẩn hiệu năng hoàn toàn mới cho cộng đồng công nghệ. Mặc dù công cụ này do chính Google phát triển và tối ưu, nhưng vị trí dẫn đầu không thuộc về hệ sinh thái Gemini mà gọi tên các đại diện từ nhà đối thủ. Sự phân hóa rõ rệt ở nhóm đầu bảng cho thấy tốc độ cải tiến thuật toán vượt bậc của thế hệ kiến trúc GPT-5.
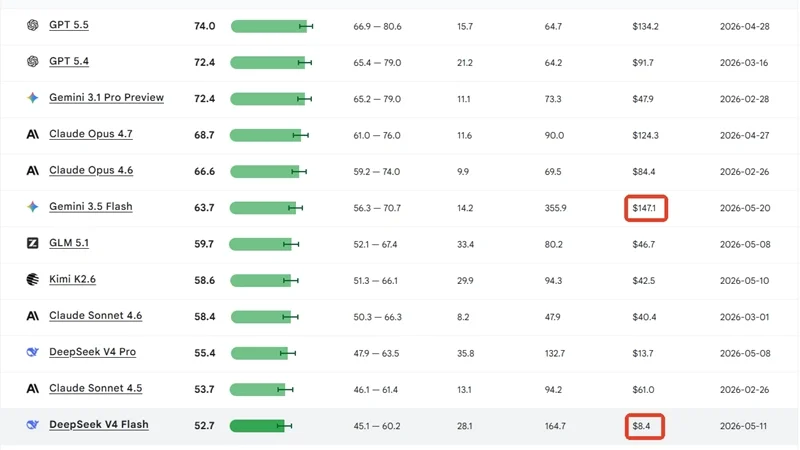
Nhìn vào số điểm chi tiết được công bố, cấu trúc phân tầng năng lực giữa các mô hình dẫn đầu được thể hiện rõ nét qua bảng thống kê sau:
| Thứ hạng | Mô hình AI | Điểm số Android Bench |
| Hạng 1 | GPT-5.5 | 74.0 điểm |
| Hạng 2 | GPT-5.4 | 72.4 điểm |
| Hạng 3 | Gemini 3.1 Pro Preview | 72.4 điểm |
| Hạng 4 | Claude Opus 4.7 | 68.7 điểm |
| Hạng 5 | Claude Opus 4.6 | 66.6 điểm |
Kết quả cho thấy GPT-5.5 xuất sắc cán đích ở vị trí số 1, với mức điểm ấn tượng là 74.0 điểm. Ngay phía sau, phiên bản tiền nhiệm GPT-5.4 nắm giữ vị trí số 2 khi đạt 72.4 điểm, đồng hạng với mô hình thế hệ cũ của Google là Gemini 3.1 Pro Preview ở vị trí số 3. Hai vị trí còn lại trong top 5 lần lượt thuộc về các đại diện đến từ Anthropic là Claude Opus 4.7 với 68.7 điểm và Claude Opus 4.6 với 66.6 điểm. Sự áp đảo này chứng minh các thuật toán xử lý ngữ cảnh sâu của OpenAI vẫn đang cho ra những đoạn mã nguồn Android chuẩn chỉnh và ít lỗi hơn.
Gemini 3.5 Flash có chi phí vận hành đắt đỏ nhất
Bên cạnh thành tích cao của OpenAI, tâm điểm chú ý còn đổ dồn vào thể hiện của Gemini 3.5 Flash. Được Google ra mắt tại sự kiện I/O 2026, mô hình này được kỳ vọng giải pháp AI thế hệ mới có tốc độ phản hồi nhanh gấp 4 lần các đối thủ, mang khả năng lập trình vượt trội cho các hệ thống Agent phức tạp. Tuy nhiên, những gì diễn ra trên thực tế lại hoàn toàn trái ngược.

Thay vì lọt vào nhóm thứ hạng cao, Gemini 3.5 Flash chỉ ngậm ngùi đứng ở vị trí thứ 6 với số điểm khiêm tốn là 63.7 điểm, bị đánh bật ra khỏi Top 5 mô hình xuất sắc nhất. Điều đáng nói không chỉ nằm ở mức điểm số dưới kỳ vọng, mà hệ thống dữ liệu của Android Bench còn bóc trần một sự thật về tính hiệu quả kinh tế của mô hình này.
Cụ thể, khi thực hiện các tác vụ Android, mô hình này bị rơi vào trạng thái lặp lại hoặc xử lý luồng dữ liệu kém tối ưu, dẫn đến những con số vận hành gây choáng váng:
- Mức tiêu thụ token trung bình: Mô hình này ngốn tới 355.9 triệu Tokens cho một chuỗi kiểm thử. Con số này cao gấp khoảng 5.5 lần so với lượng token mà nhà vô địch GPT-5.5 cần để hoàn thành cùng một khối lượng công việc.
- Chi phí cho mỗi lần chạy: Lượng token khổng lồ đã đẩy chi phí cho mỗi lần chạy lên tới 147.1 USD (tương đương khoảng 996.1 nhân dân tệ). Mức giá này biến một mô hình vốn mang mác "Flash" (giá rẻ, tốc độ nhanh) trở thành cái tên đắt đỏ nhất trên toàn bộ bảng xếp hạng.
- So sánh với các đối thủ cùng phân khúc: Khi đặt lên bàn cân với người đàn anh Gemini 3.1 Pro Preview, sự bất hợp lý càng rõ rệt. Phiên bản Pro cũ không chỉ giải quyết bài toán tốt hơn hẳn (72.4 điểm), mà chi phí vận hành của nó chỉ bằng 1/3 so với phiên bản 3.5 Flash mới. Điều này khiến giới lập trình viên cực kỳ e ngại khi có ý định tích hợp cấu trúc mới này vào quy trình làm việc thực tế.
DeepSeek V4 Flash nổi bật nhờ hiệu quả chi phí
Ở nửa dưới của bảng xếp hạng, thị trường lại chứng kiến một xu hướng dịch chuyển vô cùng thú vị từ các đại diện công nghệ châu Á, nơi bài toán tối ưu hóa chi phí được giải quyết một cách triệt để. Trong khi các mô hình phương Tây đang sa lầy vào cuộc đua tăng kích thước mô hình và đẩy chi phí lên cao, thì các tên tuổi như GLM 5.1, Kimi K2.6 hay DeepSeek V4 Pro đang tạo nên một phân khúc đầy tiềm năng.

Nổi bật trong nhóm này chính là cấu trúc mã nguồn mở DeepSeek V4 Flash. Dù chỉ đứng ở vị trí khiêm tốn là thứ 12 trên bảng tổng sắp, mô hình này lại là cái tên khiến các nhà phát triển ứng dụng độc lập phải đặc biệt lưu tâm nhờ tỷ lệ hiệu năng trên giá thành vô cùng ấn tượng:
- Điểm số trên Android Bench: Đạt 52.7 điểm, một mức hiệu năng tương đối ổn định, đủ sức giải quyết các tác vụ lập trình và sửa lỗi ở mức độ cơ bản đến trung bình.
- Chi phí vận hành thấp: Để hoàn thành toàn bộ chuỗi 100 tác vụ kiểm thử, mô hình này chỉ tiêu tốn của người dùng vỏn vẹn 8.4 USD (tương đương khoảng 56.9 nhân dân tệ).
- Gemini 3.5 Flash đắt gấp 17.5 lần DeepSeek V4 Flash: Khi đặt hai mô hình "Flash" cạnh nhau, sự chênh lệch trở nên vô cùng cực đoan. Chi phí của đại diện nhà Google cao gấp 17.5 lần đối thủ, trong khi khoảng cách về chất lượng xử lý tác vụ lập trình không hề mang lại sự khác biệt tương xứng. Đây là một minh chứng rõ ràng cho thấy không phải cứ dán nhãn "Flash" là sẽ mang lại giải pháp tiết kiệm cho doanh nghiệp.
Cuộc đua mô hình AI giờ đây không còn nằm ở lý thuyết hay trang giấy. Khi bước vào môi trường sản xuất thực tế, năng lực và tính thực dụng kinh tế mới là yếu tố quyết định sự sinh tồn của một mô hình. Thứ hạng thấp của Gemini 3.5 Flash nêu trên là lời cảnh tỉnh cho xu hướng thần thánh hóa các phiên bản phần mềm mới. Đối với cộng đồng lập trình viên và các doanh nghiệp, một mô hình AI xuất sắc phải là sự dung hòa hoàn hảo giữa độ chính xác của câu lệnh đầu ra với bài toán ngân sách phân bổ trên từng token dữ liệu.
Xem thêm
- Google nâng cấp Gemini Live với Memory và Connected Apps
- OpenRouter ra mắt mô hình AI Fusion API tối ưu hiệu năng và chi phí
- Grok Imagine Video 1.5 ra mắt tạo video AI 720p chỉ trong 25 giây
- AI dự đoán World Cup 2026 Tây Ban Nha là ứng viên vô địch số một
- Gemini 3.5 Live Translate trình làng dịch trực tiếp hơn 70 ngôn ngữ
- Google giảm giá AI Plus còn 5 USD, tăng gấp đôi dung lượng lưu trữ
- Google mở miễn phí loạt tính năng AI cao cấp trên Gemini
- Giao diện Android Auto 2026 lột xác, tích hợp AI Gemini và Maps 3D
- Toàn bộ bất ngờ tại The Android Show: Android 17 & Gemini Intelligence đã sẵn sàng!
- Trước thềm Google I/O 2026: Gemini Spark lộ diện đối đầu Claude Cowork


























































.jpg)


























.png)




















































{kind=link}
Mời bạn cùng thảo luận